
 Ph.D. Candidate at UvA
Ph.D. Candidate at UvAHi, greetings from Zeyu. I am midway through my Ph.D. studies, supervised by Prof. Sebastian Schelter, Dr. Iacer Calixto and Prof. Paul Groth. My research sits at the intersection of machine learning and relational data management. Right now, I’m especially interested in building foundation models that can make better sense of structural data. I’m also exploring how to make these models both efficient and usable, so they scale well to real-world complex systems.
I am open to any kind of connection and collaboration.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
University of AmsterdamINDELab@Informatics Institute
Ph.D. CandidateNov. 2022 - present -
 Eindhoven University of TechnologyMSc. in Computer ScienceAug. 2020 - Oct. 2022
Eindhoven University of TechnologyMSc. in Computer ScienceAug. 2020 - Oct. 2022 -
 Harbin Institute of TechnologyBSc. in Computer Science & EngineeringAug. 2016 - Jun. 2020
Harbin Institute of TechnologyBSc. in Computer Science & EngineeringAug. 2016 - Jun. 2020
Honors & Awards
-
Amandus H. Lundqvist (ALSP) Full Scholarship2020 - 2022
-
Swiss-European Modility Programme Grant2021
-
International Experience Fund FIE Scholraship2021
-
National 2nd Prize in Chinese Undergraduate Computer Design Contest2018
-
Model Student of Academic Record of Harbin Institute of Technology2018
News
Selected Publications (view all )
A Deep Dive Into Cross-Dataset Entity Matching with Large and Small Language Models
Zeyu Zhang, Paul Groth, Iacer Calixto, Sebastian Schelter
International Conference on Extending Database Technology (EDBT) 2025
We propose a new challenge that integrates two practical constraints into conventional entity matching (EM) tasks to better align with real-world deployment scenarios. A comprehensive evaluation of eight matching methods across 11 datasets provides key insights into model selection and data profiling.
A Deep Dive Into Cross-Dataset Entity Matching with Large and Small Language Models
Zeyu Zhang, Paul Groth, Iacer Calixto, Sebastian Schelter
International Conference on Extending Database Technology (EDBT) 2025
We propose a new challenge that integrates two practical constraints into conventional entity matching (EM) tasks to better align with real-world deployment scenarios. A comprehensive evaluation of eight matching methods across 11 datasets provides key insights into model selection and data profiling.
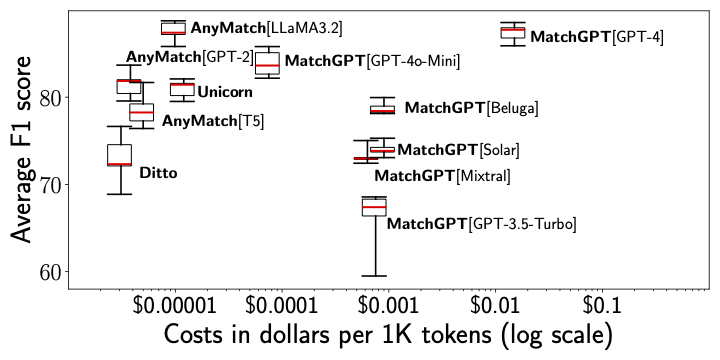
AnyMatch--Efficient Zero-Shot Entity Matching with a Small Language Model
Zeyu Zhang, Paul Groth, Iacer Calixto, Sebastian Schelter
GoodData Workshop, AAAI 2025
We introduce AnyMatch, a novel framework for building effective and efficient entity matching systems. AnyMatch leverages small language models and borrows idea from instruction tuning to diversify the training corpus, refining the model through multiple data selection strategies. The GPT-2 variant of AnyMatch ranks second among baseline models, achieving an F1 score only 4.4$\%$ lower than GPT-4 in a zero-shot setting, while reducing costs by a factor of 3,899.
AnyMatch--Efficient Zero-Shot Entity Matching with a Small Language Model
Zeyu Zhang, Paul Groth, Iacer Calixto, Sebastian Schelter
GoodData Workshop, AAAI 2025
We introduce AnyMatch, a novel framework for building effective and efficient entity matching systems. AnyMatch leverages small language models and borrows idea from instruction tuning to diversify the training corpus, refining the model through multiple data selection strategies. The GPT-2 variant of AnyMatch ranks second among baseline models, achieving an F1 score only 4.4$\%$ lower than GPT-4 in a zero-shot setting, while reducing costs by a factor of 3,899.